Statistics¶
Questions¶
Notebook Cell
Solution:
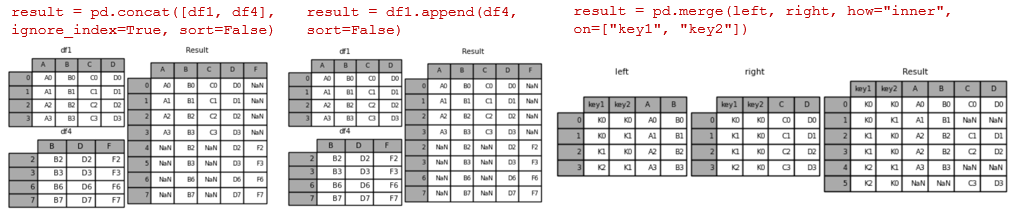
A very high level difference is that merge() is used to combine two (or more) dataframes on the basis of values of common columns (indices can also be used, use left_index=True and/or right_index=True), and concat() is used to append one (or more) dataframes one below the other (or sideways, depending on whether the axis option is set to 0 or 1).
join() is used to merge 2 dataframes on the basis of the index; instead of using merge() with the option left_index=True we can use join().
Notebook Cell
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
def normal_sample_generator(N):
# can be done using np.random.randn or stats.norm.rvs
#x = np.random.randn(N)
x = stats.norm.rvs(size=N)
num_bins = 20
plt.hist(x, bins=num_bins, facecolor='blue', alpha=0.5)
y = np.linspace(-4, 4, N)
bin_width = (x.max() - x.min()) / num_bins
plt.plot(y, stats.norm.pdf(y) * N * bin_width)
plt.show()
normal_sample_generator(10000)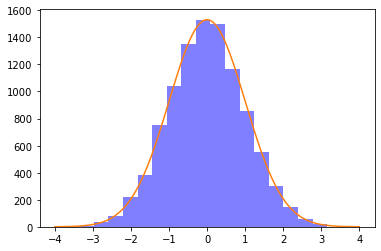
Solution:
Solution pending, [Reference material link](Given a random Bernoulli trial generator, how do you return a value sampled from a normal distribution?)
Notebook Cell
# Interquartile distance is the difference between first and third quartile
# first let's generate a list of random numbers
import random
import numpy as np
li = [round(random.uniform(33.33, 66.66), 2) for i in range(50)]
print(li)
qtl_1 = np.quantile(li,.25)
qtl_3 = np.quantile(li,.75)
print("Interquartile distance: ", qtl_1 - qtl_3)[54.81, 65.68, 63.85, 58.29, 60.14, 53.23, 52.58, 51.62, 61.6, 57.85, 51.37, 38.7, 35.87, 33.95, 61.65, 33.59, 61.33, 44.97, 62.49, 39.67, 51.03, 45.79, 60.99, 60.49, 64.8, 46.16, 46.61, 34.06, 37.78, 56.72, 39.62, 61.38, 55.27, 40.53, 49.31, 58.95, 37.49, 34.39, 60.47, 56.12, 61.41, 34.56, 58.18, 56.35, 63.59, 50.59, 61.51, 42.02, 52.43, 56.71]
Interquartile distance: -17.7275
Notebook Cell
import pandas as pd
cheeses = {"Name": ["Bohemian Goat", "Central Coast Bleu", "Cowgirl Mozzarella", "Cypress Grove Cheddar", "Oakdale Colby"], "Price" : [15.00, None, 30.00, None, 45.00]}
df_cheeses = pd.DataFrame(cheeses)
df_cheeses['Price'] = df_cheeses['Price'].fillna(df_cheeses['Price'].median())
df_cheeses.head()Loading...